Overview
Shinylive represents a paradigm shift in how Shiny applications are deployed and executed. Instead of running on a computational server, these applications execute entirely within a web browser after being downloaded. This vignette explores the transformation process from a traditional Shiny application to a Shinylive application and explains how tools like peeky can extract the source code from these browser-based applications.
The Traditional Shiny Model
In a traditional Shiny application:
- Source code resides on a computational server
- R and/or Python are installed and running on the server
- Users interact with the app through their browser, which communicates and processes the interaction on the server.
- App code remains private and inaccessible to end users
For example, consider a template for an R Shiny application:
# Traditional Shiny app structure
# app.R or (ui.R/server.R)
library(shiny)
ui <- fluidPage(
# UI elements
)
server <- function(input, output, session) {
# Server logic
}
shinyApp(ui, server)Once deployed, the server executes the application code and sends the results back to the user’s browser. This code is not accessible to the user since it runs on the server’s R process.
The Shinylive Transformation: From Server to Browser
Shinylive represents a revolutionary approach to Shiny applications by enabling them to run entirely within a web browser. Unlike traditional Shiny apps that require continuous server communication, Shinylive applications operate like modern web pages—downloaded once and executed locally in the user’s browser.
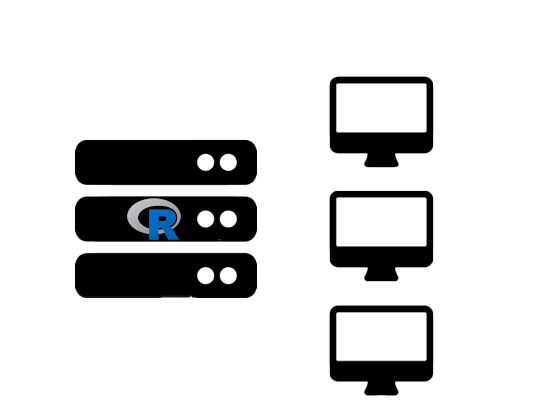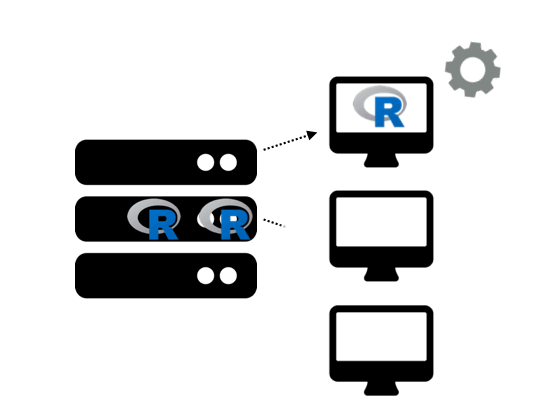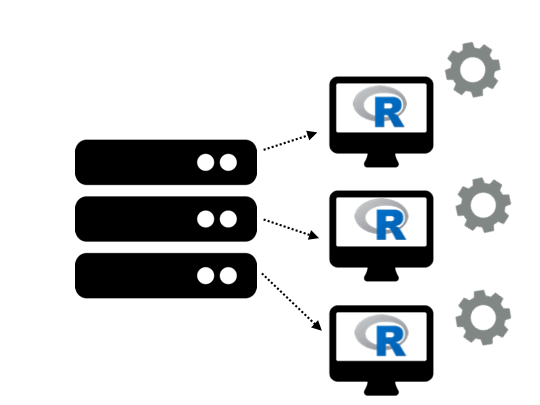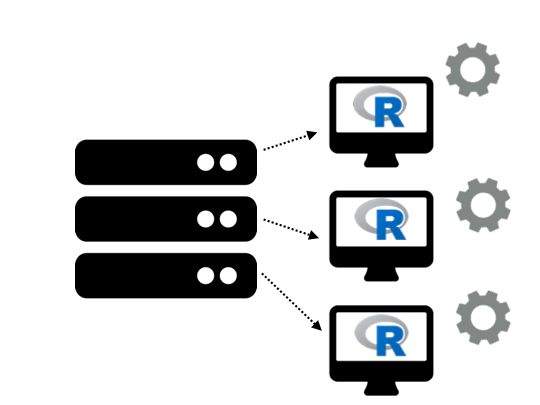
This transformation involves arguably three key steps: Code Preparation, Conversion Process, and Browser Deployment.
Step 1: Code Preparation
The initial phase of converting a Shiny application to Shinylive requires careful preparation of your application code. While most core Shiny functionality remains unchanged, several key areas need attention.
Dependency Management
Your application’s dependencies must be compatible with WebAssembly execution:
For R applications:
- Verify package availability in the webR package repository
- Consider alternative packages if preferred ones aren’t WebAssembly-compatible
- Be mindful that some packages may have reduced functionality in WebAssembly version of R.
For Python applications:
- Check if packages are included in Pyodide’s built-in package list
- For packages not in Pyodide, look for pure Python alternatives on PyPI
- Note that packages with C extensions typically won’t work unless specifically compiled for the WebAssembly version of Python.
File System Considerations
Browser-based applications handle files differently than traditional server applications:
- Use relative paths for all file references
- Avoid assumptions about file system access or operating system-specific paths
- Maintain a clear directory structure with data files in the application directory
External Resource Management
Applications running in WebAssembly require specialized approaches for accessing external resources via an API due to browser security constraints and the WebAssembly runtime environment.
Pre-bundling Data
For static or infrequently updated data, bundle it directly with your application. This approach ensures reliable data access and faster initial loading.
# Before: Direct API access
api_data <- fetch_from_api("https://api.example.com/data")
# After: Using pre-bundled data
# During development:
api_data <- fetch_from_api("https://api.example.com/data")
jsonlite::write_json(api_data, "data.json")
# In application:
data <- jsonlite::fromJSON("data.json")Dynamic Data Loading
For APIs that support Cross-origin resource sharing (CORS), you can fetch data directly by using download.file() (replaced with a browser-compatible download method):
# Before: Server-side API call
api_data <- fetch_from_api("https://api.example.com/data")
# After: Browser-compatible download
download.files("https://api.example.com/data", "data.json")
data <- jsonlite::fromJSON("data.json")To ease future maintanence, we suggest documenting any WebAssembly-specific modifications.
Step 2: The Conversion Process
Converting a Shiny application to Shinylive involves transforming your application into a browser-compatible format. This process is automated through dedicated conversion tools for both R and Python environments.
Initiating the Conversion
We can convert a shiny application found in myapp/ directory to a Shinylive application via either {r-shinylive} or {py-shinylive}.
For R Applications:
# Install the package if needed
# install.packages("shinylive")
# Convert the application
shinylive::export(
appdir = "myapp", # Source directory
destdir = "_site", # Output directory
verbose = TRUE # Show conversion progress
)For Python Applications:
# Install the package if needed
# pip install shinylive
# Convert the application
shinylive export myapp _siteBehind the Scenes
The conversion process involves three unique stages described next.
File Collection
The system aggregates all application components:
- Application source code (R/Python files)
- Data files and datasets
- Web assets (images, stylesheets, scripts)
- Configuration files
- Documentation files
Metadata and Manifest Generation
The system creates a comprehensive app.json manifest that catalogs and stores all application components.
The original Shiny application shown would be converted to:
[
{
"name": "app.R",
"content": "library(shiny)\nui <- fluidPage(...) ...",
"type": "text"
},
{
"name": "data/dataset.csv",
"content": "date,value,category\n2024-01-01,42,A",
"type": "text"
},
{
"name": "www/assets/logo.png",
"content": "iVBORw0KGgoAAAANSUhEUgAA...",
"type": "binary"
},
{
"name": "www/styles/custom.css",
"content": ".dashboard-container { padding: 2rem; }",
"type": "text"
}
]Runtime Environment Setup
The conversion tool configures the appropriate WebAssembly-based runtime environment.
For R Applications:
- Configures WebR environment
- Sets up required R packages
- Establishes communication bridges between WebR and the browser
For Python Applications:
- Configures Pyodide environment
- Sets up Python package dependencies
- Establishes browser-Python interop mechanisms
Each stage ensures that your application will run efficiently and reliably in a browser environment while maintaining (nearly) all its original functionality.
Step 3: Browser Deployment and Execution
Once converted, a Shinylive application can be deployed to any web server that supports HTTPS. This represents a significant departure from traditional Shiny hosting requirements, as the application now runs entirely in the user’s browser.
That said, we still have a few choices to make regarding how it is “deployed” or shared.
Local Deployment
If we’re wanting this to be a local application, we cannot directly click on the generated HTML file to view the application (without modify browser security settings). Instead, we need to use a “Live Server” to view the application. This can be achieved with either:
- Use VSCode’s Live Server extension
- Python’s
http.servermodule - R’s
httpuvpackage
The latter two are suggested directly after conversion.
Global Deployment
If we can share our application, then any static hosting platforms will suffice. For example, we could use anyone of the following services to make our application available:
- GitHub Pages (free, integrated with GitHub)
- Netlify (robust CDN, automatic builds)
- Vercel (excellent performance, good for SPAs)
- Amazon S3 + CloudFront (scalable, cost-effective)
Global Deployment Tutorials
For step-by-step guidance to deploy with GitHub Pages under a continuous deployment workflow, consult these tutorials:
-
R Shinylive in Quarto Documents
- Integration with Quarto publishing
- Document-embedded applications
-
R Shinylive GitHub Pages Deployment
- Standalone R Shiny application deployment
-
Python Shinylive GitHub Pages Deployment
- Python-specific considerations (e.g.
requirements.txt)
- Python-specific considerations (e.g.
Application Runtime Flow
Once deployed, the application follows this execution sequence:
-
Runtime Initialization
- Browser loads WebR or Pyodide environment
- WebAssembly modules are initialized
- Runtime dependencies are configured
-
Application Loading
- System fetches and parses
app.json - Application files are extracted and loaded
- Resources are prepared for execution
- System fetches and parses
-
UI Initialization
- Interface elements are rendered
- Event listeners are established
- WebAssembly runtime is connected to UI
-
Client-Side Execution
- All computation occurs in the user’s browser
- No server communication required
- Real-time interactivity through WebAssembly
This sequence provides a seamless, computation server-independent experience while maintaining the (nearly) full power and interactivity of Shiny applications.
Understanding and Extracting Shinylive Applications with peeky
The peeky package provides tools to examine and extract source code from deployed Shinylive applications, leveraging their inherent transparency. This capability is valuable for learning, debugging, and understanding how successful Shinylive applications are structured.
There are three key functions for exploring a Shinylive application:
# For any Shinylive application type
peeky::peek_shinylive_app(
url = "https://shiny.thecoatlessprofessor.com/probability-distribution-explorer",
output_dir = "extracted-app"
)
# Specifically for standalone applications
peeky::peek_standalone_shinylive_app(
url = "https://shiny.thecoatlessprofessor.com/central-limit-theorem/",
output_dir = "extracted-standalone-app"
)
# For Quarto-embedded applications
peeky::peek_quarto_shinylive_app(
url = "https://coatless-quarto.github.io/r-shinylive-demo/",
output_path = "extracted_quarto",
output_format = "app-dir" # or "quarto"
)Application Reconstruction
The extracted content is automatically reconstructed into a fully functional application structure.
For example, with our motivating Shiny example, we would have:
sample-app/
├── app.R # Application entry point
├── data/ # Data directory
│ └── data/dataset.csv
├── www/ # Web assets
│ ├── assets/
│ │ └── logo.png
│ └── styles/
│ │ └── custom.css
└── shinylive_metadata.json # Configuration (Quarto-apps only)Handling Quarto-Embedded Applications
When working with Quarto documents containing multiple Shinylive applications, peeky offers two reconstruction approaches:
# Extract as separate application directories
peeky::peek_quarto_shinylive_app(
url = "https://quarto-ext.github.io/shinylive",
output_format = "app-dir",
output_path = "extracted_quarto"
)
# Results in:
# extracted_quarto/
# ├── app_1/
# ├── app_2/
# ├── app_3/
# └── app_4/
# Reconstruct as a new Quarto document
peeky::peek_quarto_shinylive_app(
url = "https://quarto-ext.github.io/shinylive",
output_format = "quarto",
output_path = "extracted_quarto.qmd"
)
# Results in a single .qmd file containing all applicationsThis flexibility in extraction formats supports various use cases, from studying individual applications to reproducing complete Quarto documents with embedded Shinylive functionality.
Security Implications
When deploying Shinylive applications that run entirely in the browser, developers must carefully consider the implications of client-side code transparency. Unlike traditional server-based applications, these browser-based apps can be downloaded, inspected, and reconstructed by users, creating unique security challenges.
The client-side nature of these applications means that all source code—whether it’s R, Python, or SQL queries—becomes accessible to anyone with basic knowledge of browser developer tools or peeky. This exposure isn’t limited to just the code itself; it extends to bundled datasets, configuration files, and any other resources packaged with the application.
Security-critical elements like API keys, database credentials, and authentication tokens require special handling. Including these in client-side code is equivalent to making them public, as they can be easily extracted from the browser’s memory or network requests. Such sensitive credentials should always be managed through secure server-side mechanisms.
Perhaps even more critically, organizations must carefully assess how they handle proprietary intellectual property. Any business logic, algorithms, or unique computational methods implemented in client-side code become vulnerable to inspection and replication. This creates a fundamental tension between the convenience of client-side processing and the need to protect valuable intellectual property. Organizations should conduct thorough risk assessments to determine which components can safely run in the browser and which must be protected behind server-side APIs. Complex algorithms, sensitive business rules, and proprietary calculations are often better suited for server-side implementation where they remain shielded from reverse engineering.
Best Practices for Deployment
While Shinylive represents an exciting advancement in browser-based applications, the best practices are a work in progress. We suggest organizations looking to adopt Shinylive look toward the following guidelines…
Design for Transparency
Begin your development process with the understanding that all application code will be visible to users. This fundamental characteristic should inform decisions about what functionality to implement client-side versus server-side. Structure your code with this visibility in mind, including clear documentation and well-organized components that can withstand public scrutiny.
Data and Algorithm Protection
Exercise extreme caution with sensitive information in Shinylive applications. Avoid including any Personal Identifiable Information (PII), protected health information (PHI), or confidential business data in the client-side portion of your application. Similarly, proprietary algorithms and critical business logic should not be implemented in the browser where they can be inspected and potentially replicated.
Clear Licensing and Attribution
Include explicit licensing terms in your application’s source code. Place these at the beginning of each of your files, clearly stating:
- The type of license (e.g., MIT, Apache, GPL)
- Copyright information
- Any usage restrictions or requirements
- Attribution requirements for dependencies
Hybrid Deployment Strategy
For applications requiring both public and protected components, consider implementing a hybrid architecture:
- Use Shinylive for non-sensitive, computationally intensive operations that benefit from client-side processing
- Leverage traditional Shiny server deployment for handling sensitive data and protected business logic
- Implement secure API endpoints for communication between Shinylive and server-side components
- Establish clear boundaries between public and private functionality
This hybrid approach allows you to leverage Shinylive’s benefits while maintaining necessary security controls for sensitive operations. When implementing this strategy, ensure proper authentication and authorization mechanisms are in place for any server-side interactions.
Fin
The transformation from traditional Shiny to Shinylive represents a fundamental shift in how data science applications are delivered. While this brings advantages in deployment and accessibility, it also requires developers to embrace transparency and adjust their development practices accordingly. Tools like peeky serve as powerful reminders of this transparency, offering developers insights into how their applications will be perceived and potentially analyzed by end users.
Looking ahead, this paradigm shift suggests a future where data science applications are increasingly leveraging edge or client-side computation while maintaining careful boundaries around sensitive operations. Success in this new landscape requires balancing the benefits of browser-based execution with thoughtful protection of intellectual property and sensitive data. As the ecosystem matures, we expect to see emerging patterns and best practices that help developers navigate these considerations effectively.
Acknowledgements
Thanks to the Shinylive, webR and Pyodide teams for enabling browser-based data science.